
Introdução
A inteligência artificial (IA) generativa e os assistentes de código estão revolucionando a forma como desenvolvemos software. Em poucos anos, essas tecnologias passaram de conceitos teóricos a ferramentas essenciais para muitos desenvolvedores. A popularização permitiu que os famosos LLMs(modelos de linguagem grande) fossem treinados para produzir código e nos apoiar em diversas tarefas do dia a dia, tornando os processos mais eficientes.
Os assistentes de código como o Github Copilot, por sua vez, estão mudando a forma como escrevemos código. Temos a disposição um chat que nos apoia a tirar dúvidas, gerar novas ideias e até auto completar nosso código. Isso não apenas economiza tempo, mas também melhora a qualidade do que produzimos, aumentando a nossa velocidade para correção de possíveis erros.
Atualmente, temos diversas soluções que oferecem soluções no formato “Copilotizado”. Entretanto, para nós brasileiros, os preços podem ficar proibitivos devido à conversão do dólar. Considerando isso, a ideia aqui é mostrar como você pode ter o seu próprio “Code Assistant” a um custo mais baixo e até mesmo de graça, usando recursos totalmente locais.
Setup AWS e Bedrock
Para conseguir autenticar corretamente o Continue com o Bedrock, basta ter configurado o awscli com as suas credenciais. Um simples aws configure no terminal será o suficiente para autenticar. Confira a doc oficial da AWS para mais detalhes de como fazer o setup.
Habilitando os modelos no Bedrock
Para começar a usar os LLMs através do serviço da Amazon, primeiro precisar solicitar quais modelos desejamos que estejam ativos em nossa conta. Basta navegar até a console do serviço, rolar a página até o final e clicar em Model Access, no canto inferior esquerdo.
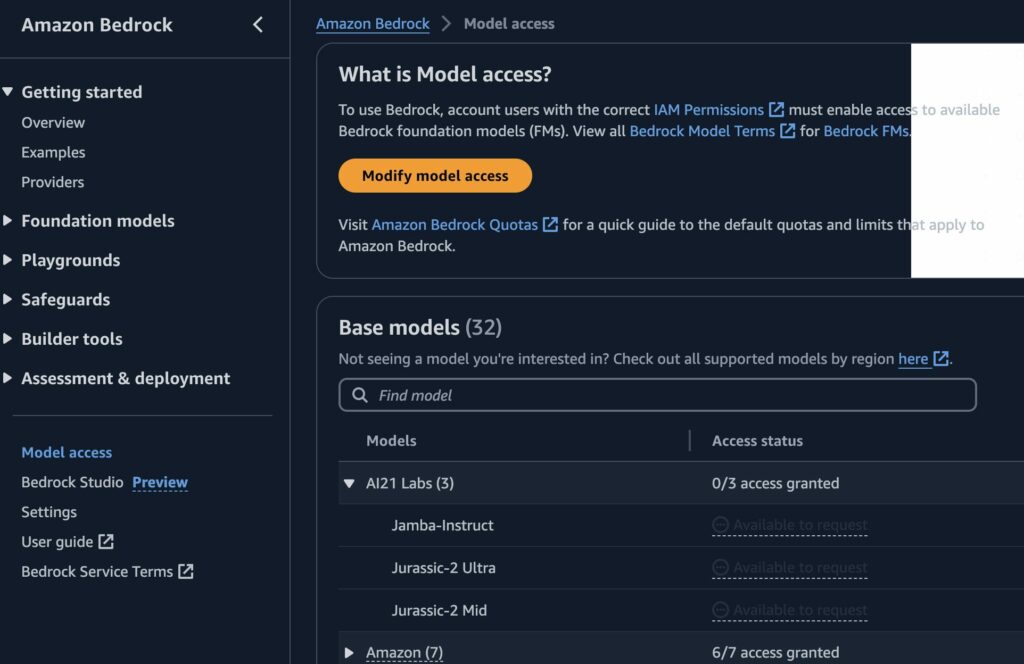
Clicando em Modify model access, podemos solicitar o acesso aos modelos que desejamos utilizar. Aqui fazemos somente o pedido de liberação, habilitar os modelos sem utilizá-los não gera nenhum custo. Abaixo temos alguns modelos que foram selecionados na conta de teste.
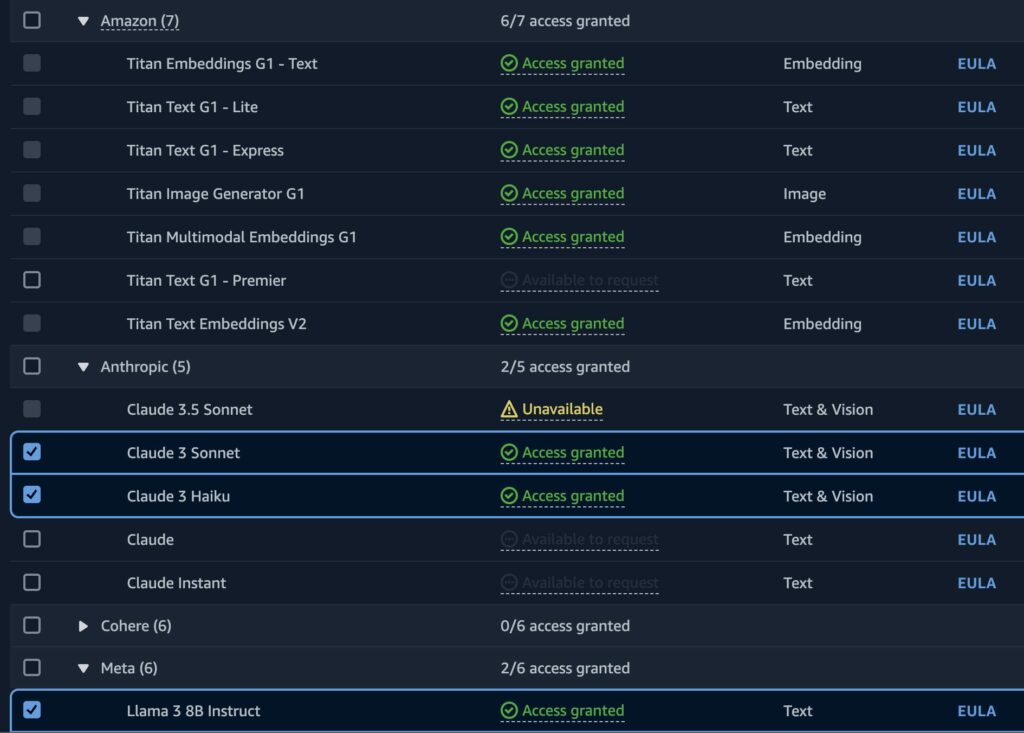
Após selecionarmos os modelos que desejamos habilitar, basta irmos até o canto inferior direto e clicar em next. Em seguida, clicamos em submit para que a solicitação seja enviada. Feito isso basta aguardar alguns minutos para que os modelos fiquem disponíveis para uso, que normalmente é um processo bem rápido.
Continue: Plugin Code Assistant para o VSCode
O Continue é um plugin que nos permite integrar na nossa IDE diversos providers com modelos de LLM. Podemos usar a OpenAI, Amazon Bedrock, Ollama e muitos outros. Com ele, você pode ter seu próprio ” Code Assistant” para lhe ajudar a escrever códigos e responder algumas dúvidas sem a necessidade de fazer o pagamento fixo de um valor mensal.
Para começar a usar o Continue, você pode instalá-lo direto via IDE no VS Code ou em alguma outra que seja da JetBrains(IntelliJ, Pycharm, etc). Basta seguir os passos simples de instalação e você estará pronto para começar a usar a ferramenta em poucos minutos.
Podemos destacas os seguintes pontos a respeito de suas funcionalidades:
- Auto complete de código(BETA): O Continue oferece a funcionalidade de auto completar códigos, entretanto, a funcionalidade ainda não está na versão estável. Nos meus testes usei o Ollama para rodar um modelo local(llama3:8b) com uma RTX 3050 8GB. Da para usar mas o desempenho deixa um pouco a desejar, neste formato de uso local.
- Chat: Permite que façamos perguntas através do Chat, semelhante ao que vemos no GitHub Copilot. Temos histórico das interações, contexto das mensagens enviadas, etc.
- Multi provider: Como mencionado no início do texto, temos compatibilidade com diversos providers para utilizarmos os LLMs. Inclusive, podemos usar tudo 100% local através do Ollama. Uso de GPU aqui é mandatório se o intuito é rodar local, preferencialmente alguma da NVIDIA, muito embora o Ollama também tenha suporte para GPUs AMD.
- Modularidade: Além de todas as capacidades nativas, ele também permite que você crie suas próprias customizações através de atalhos para trazer mais contexto, como @terminal(pegando o que está no seu terminal), @codebase(responde coisas baseado em sua Code Base, aberta na IDE), @url(trás informações de uma URL que for passada) e várias outras funcionalidades já prontas. Também é possível criar comando usando a estrutura /comando, além dos que já estão prontos.
- Indexação de dados: O Continue executa continuamente a indexação da sua Code Base localmente, permitindo que possamos fazer perguntas diretamente usando o nosso código como contexto. Basta digitar @codebase no chat, assumindo que tenha sido configurado como mostraremos mais abaixo.
- Integração com IDEs: O Continue se integra perfeitamente com IDEs populares como VS Code e as versões da JetBrains, permitindo que você trabalhe de forma mais eficiente e produtiva.
Extensão no VSCode

Para instalar é bem tranquilo, só ir na aba de extensões do VSCode e buscar por “Continue”, como mostrado na imagem acima. Na configuração padrão, a logo da ferramenta aparecerá do lado esquerdo, na barra de aplicações da IDE.

Esta é a tela onde fazemos o uso do Chat e exploramos o histórico, indexação, modelos cadastrados e as configurações. Todos os parâmetros são configurados através de um arquivo chamado config.json. No canto inferior direito, podemos clicar na engrenagem para abrir as configurações.
Consulte sempre a documentação oficial para poder saber quais parâmetros você pode utilizar. Aqui abaixo vou deixar um exemplo de configuração para o VSCode com alguns modelos locais configurados, assim como o Bedrock.
Acima temos um arquivo base com várias configurações possíveis, você pode alterar conforme sua necessidade. Neste modelo já temos os pontos principais configurados: Modelos de providers diferentes, Embeddings, Code Completion e comando para trazer contexto durante o prompt.
Lembre-se:
* Altere o SystemMessage para o contexto que for mais adequado para você. Vai ajudar a direcionar as respostas do LLM para o contexto informado, melhorando a precisão do que for solicitado.
* Para usar os modelos do Ollama você precisa que ele já esteja em execução e que os mesmos tenham sido baixados. Consulte a documentação oficial para informações sobre como instalá-lo e usá-lo.
* Caso você esteja usando o Ollama diretamente na sua máquina, configure o apiBase como http://localhost:11434
Gerando código com o Chat
Para ilustrar a funcionalidade usarei um prompt bem simples: “Gere um código em python que faça uma requisição HTTP para um site. Verifique o status code e mostre a mensagem de “site ok” quando o retorno for 200. Quando a resposta for diferente de 200, mostre qual foi a mensagem de erro e o status code. Pense passo a passo como um desenvolvedor de software.”
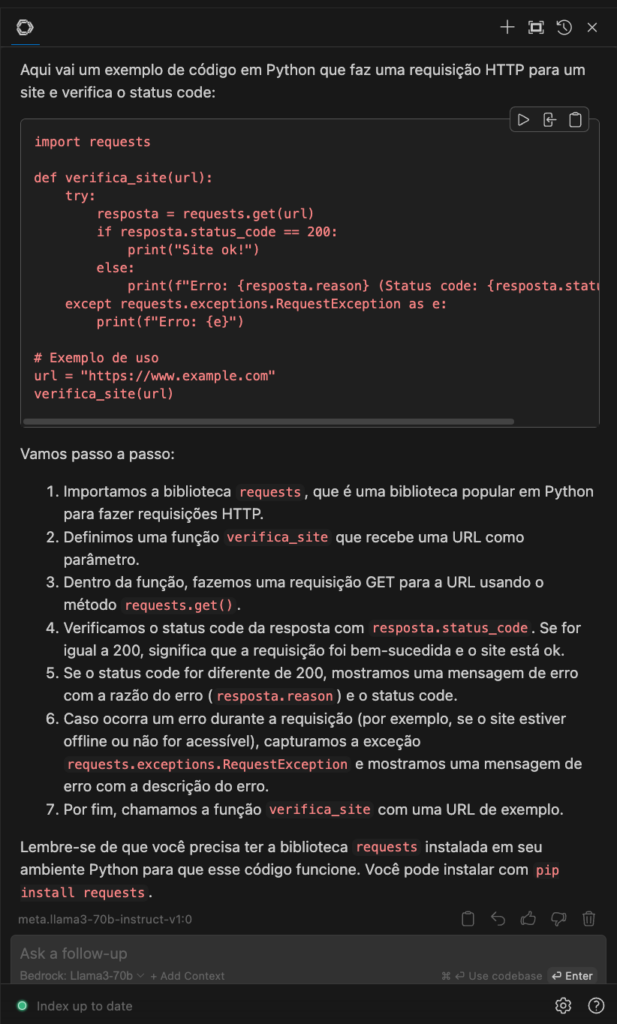
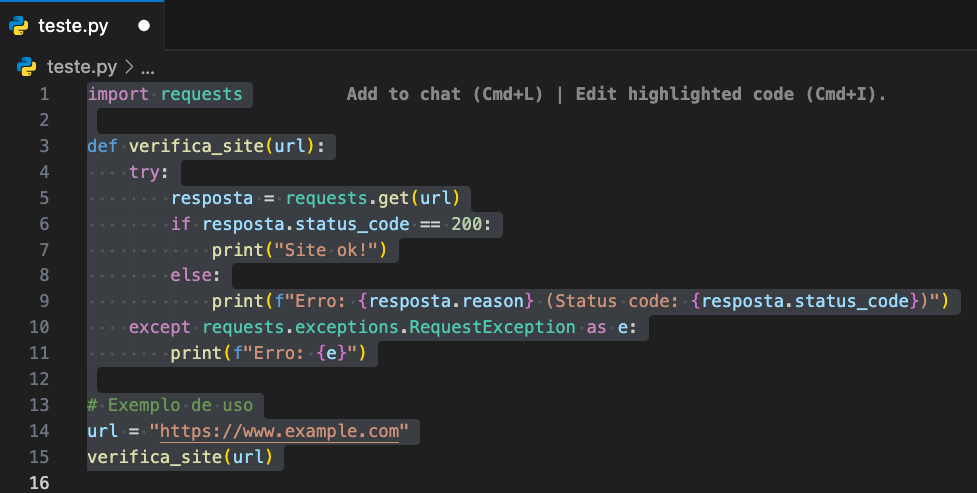
Copiei e colei o código gerado e executei no terminal, tudo funcionou como esperado. Usei o endereço https://www.example.com e https://www.example.coma para simular uma execução com sucesso e outra com falha.

Conclusão
Por ser um exemplo simples, é natural que o código gerado seja algo funcional. Mas lembre-se, o LLM não faz mágica. Avalie sempre o conteúdo gerado e use-o como base para acelerar o desenvolvimento, afinal, nem sempre tudo funcionará de forma adequada na primeira tentativa.
Como vimos aqui, o Continue pode ser bem versátil e também sair 100% grátis quando combinado com o Ollama. Aproveite que a ferramenta possui uma versão free e construa seu próprio Code Assistant!
No mais, usar o Bedrock também é uma mão na roda para nos permitir usar modelos maiores, como no caso do Llama3:70b que infelizmente é grande demais para rodar na minha RTX 3050.
Fiquem a vontade para compartilhar suas experiências nos comentários!